















[AWS Black Belt Online Seminar] Amazon Timestream 資料及び QA 公開 | Amazon Web Services
先日 (2020/12/16) 開催しました AWS Black Belt Online Seminar「Am [...]
https://aws.amazon.com/jp/blogs/news/webinar-bb-amazontimestream-2020/

こんにちは。
エス・エー・エス株式会社の海田です。
9月になりました。
夏の間、温度が高すぎてあまり出てこなかった「蚊」ですが、少し温度が落ち着いてきた最近はなかなか元気なようで、特に子供(娘)はよく刺されています。娘がかわいそうなので、この世からすべての蚊を駆逐できればと思うこともありますが、それはそれで生態バランス的によくないのでしょうね・・。
ハーブ系の植物を植えたりしておくといいと聞いたことがあります。来年は庭中に植えて最強のバリアを作ろうか考え中です。
それにしても、今年は特に暑かったですね・・。特に7月中旬から8月中旬くらいまでは雨が降らない日も多く、昼間は屋外で過ごすことは非常に厳しい状態だったかと思います。
実測値としてはどんな感じだったのでしょうか。
気象庁のサイト(https://www.data.jma.go.jp/risk/obsdl/index.php)では、気温、風速、気圧など、気象に関するデータをCSVでダウンロードすることができます。観測ごとに収集したデータを公開してくれているわけですね。
これはいわゆるオープンデータというやつで、自由にダウンロードし、二次利用ができるようになっています。気象のデータには必ず「いつ取得したのか」という「時刻情報」がついてきます。
この「時刻情報」と「気温」や「風速」などの観測対象の値(メトリクス)をセットにしたものを「時系列データ」と言います。今日はこの時系列データを保存するのに適したAWSのDB「Timestream」を試してみたので、それをブログのテーマにしてみたいと思います。
まずは基本から。
新人研修や実際の業務で一般的に「データベース」というと、リレーショナルデータベース(RDB)を指していることが多いかと思います。スキーマ、テーブルの中に、「行(タプル)」と「列(カラム)」があり、SQL文を使って操作します。PostgreSQL、MySQL、SQLServer、Oracle・・これらはすべてRDBです。
排他制御ができる、複数のテーブルを論理的に結合して、目的のレコード群を取り出せる・・など、RDBを利用するメリットは多々ありますが、あえて不得意なことを上げるとすれば「履歴を管理すること」だと思います。特にその履歴がリアルタイムに変化していく(例えば視聴者数、投票数、株価など)場合、その格納にRDBを使うことは適切ではありません。
そのような時間とともに変化していく値(または値の組み合わせ)を記録してく場合に適しているDBとして、「時系列DB」と言われるデータベースがあります。AWSでは「Timestream」というサービスで提供されています。2020年からリリースされたようです。
時系列データというのは、「タイムスタンプ」と「観察対象の値」の組み合わせです。気象関連のデータやオンライン配信の視聴者、リアルタイム投票数等のデータもそうですし、CPU,メモリ使用率なども時系列データとなります。時間とともに変化していく値に価値があるので、時系列データをDBに保存する場合は、一つのレコードを更新していくのではなく、行を追加して保存していく必要があります。
つまり一つの観測対象(例えばCPU使用率)のタイムスタンプごとのレコードが「蓄積」されていきます。ここ、大事なポイントです。
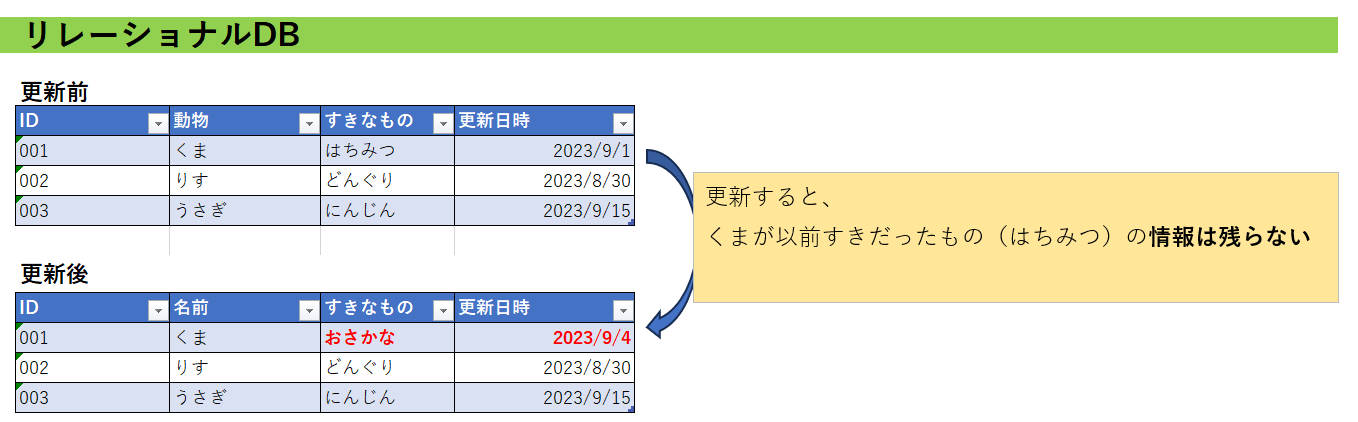
RDB等の列で「更新日時」というものはよく作成すると思います。しかしこれは時系列データのタイムスタンプとは明確に異なります。「更新日時」は、あくまでそのレコードに対する「更新日時」です。更新してしまえば、一つ前のレコードの他の情報は失われます。
一方、時系列DBの場合は、データの更新ということが原則発生しません。データはタイムスタンプとともに「蓄積」されていきます。
一応、RDBにおいて「更新日時」の他に、「シーケンス番号」等を組み合わせて「履歴管理テーブル」として運用していけばたしかに時系列データを保存できます。しかし、RDBでこれを行うと運用面でいろんな「弱み」があります。
先に示した通り、RDBでも「更新日時」+「シーケンス番号」で、履歴管理をしていくことはできます。月1回、年1回程度で行が追加されるならば、データ量も追加頻度も少ないので、問題ないでしょう。
しかし例えば毎時間もしくは毎秒、さらに多方面から大量の観測対象データのレコード追加オーダーが来た場合、RDBの負荷はとても大きくなってしまいます。そして、データを格納するストレージのサイズもたくさん必要になってしまいます。また、履歴をどこまで残しておくのか、定期的に削除するような処理を別途計画しなくてはなりません。
時系列データをRDBに保存することは不可能ではないですが、いろいろ考えなきゃいけないことがありそうです。時系列データは時系列DBに保存するのがよさそうです。Timestreamの強みを見ていきます。
Timestreamには以下の強みがあります。
いずれもマニュアルからの転載ですが、かなりすごそうですよね。
Timestreamへの時系列データの投入は、AWSCLIやプログラムに組み込んだSDKから操作することが一般的らしいのですが、今年の3月から【強み⑤】にあるように、S3にアップロードしたCSVファイルからも取り込めるようになったようです。これはかなりとっつきやすいかなと思ったので、この方法で始めてみることにしました。
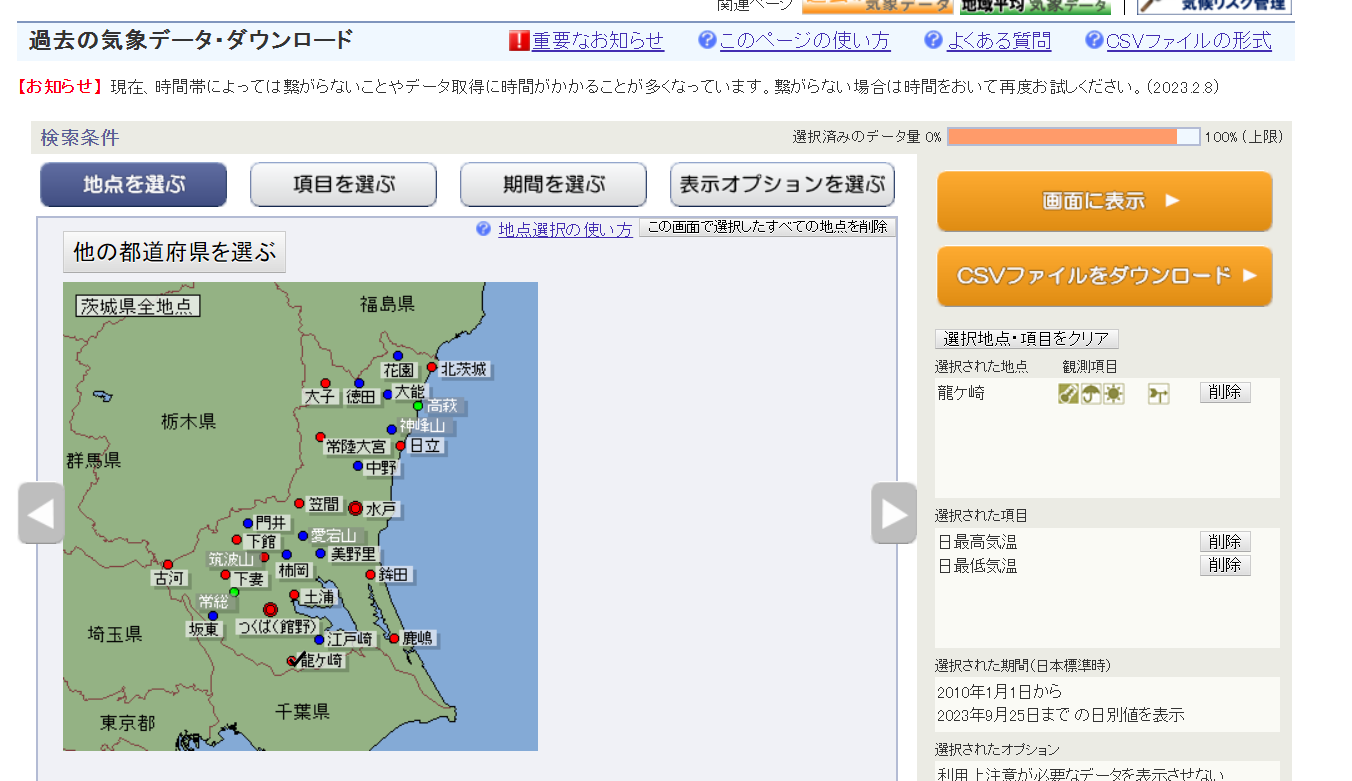
というわけで、早速気象庁のCSVデータをTimestreamに取り込んでみましょう。対象都市は日本全国どこでもいいのですが、私は茨城県在住なので茨城県龍ヶ崎市の過去の最高、最低気温の変遷を取り込んでみることにします。
気象庁(https://www.data.jma.go.jp/risk/obsdl/index.php)のサイトから、必要なデータをダウンロードしていきましょう。
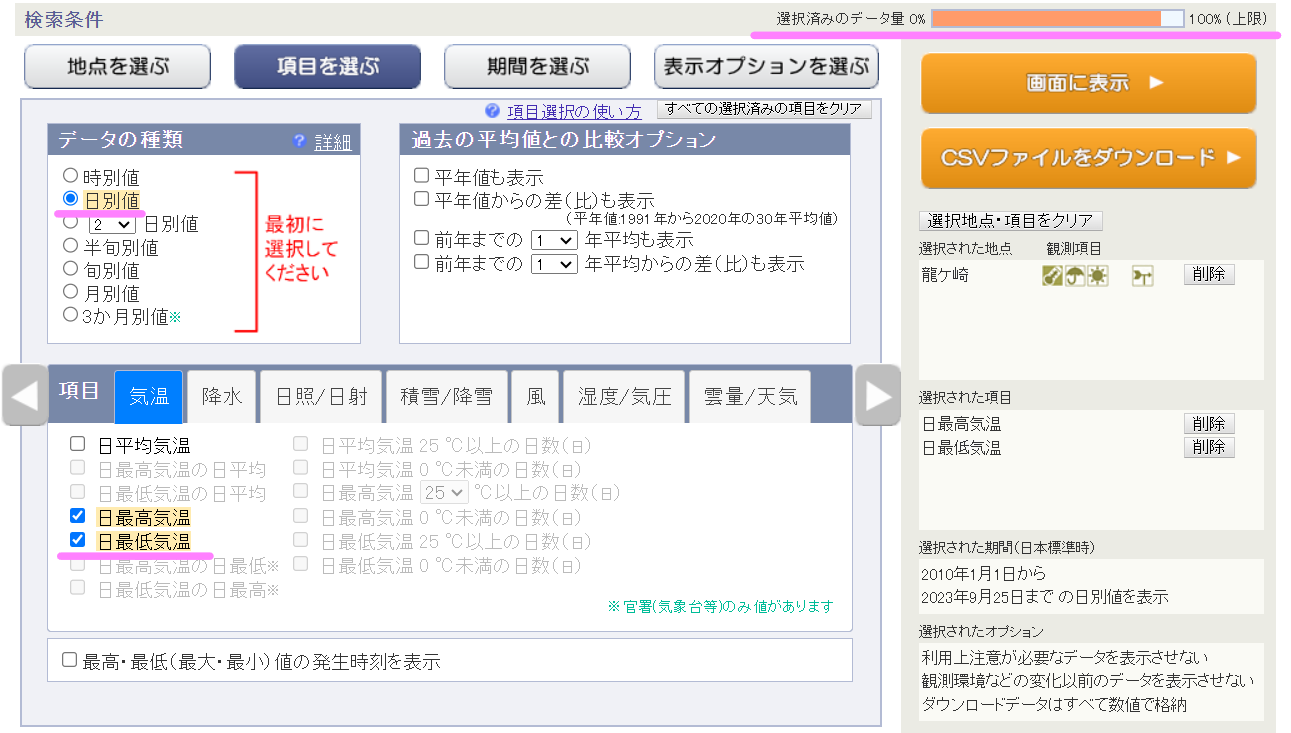
ちなみにオープンデータとしては過去100年くらいありそうですが、実は一度にDLできるサイズが決まっているようで、以下画像の通り、右上の「選択済みのデータ量」が100%以下でないとDLできません。
つまり、データの取得間隔(時別、日別)を細かくしたり、期間を長くしたり、取得する項目を多くしたりすると、取得期間が1年でも100%に近づいてしまいます。最初は100年分のデータ取り込んでやる!と思っていたのですが、なかなか手間がかかりそうなので諦めました。ひとまず2010年1月1日から、龍ヶ崎市の毎日の最高気温、最低気温だけを取得することにしました。下がそのスクショです。(これでも90%くらいいってますね)
とりあえずこれで、元ネタはDLできました。次はTimestreamで時系列DBの作成をしましょう。
Timestreamで時系列DBを作っていきます。いずれもマネジメントコンソールだけで完了します。(簡単です)
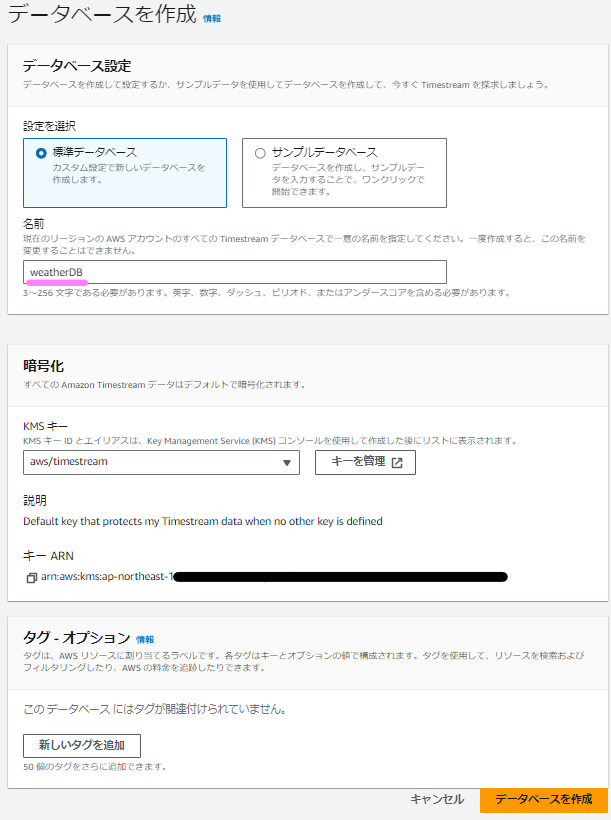
作成する必要があるのは、①データベース②テーブルの2つだけです。まずは①データベースから作っていきます。Amazon Timestreamのページから「データベースの作成」を押下します。
標準データベースを選択し、データベースの名前を入れます。「weatherDB」としておきます。その他はそのままで大丈夫で、暗号化のところはデフォルトで有効となっていて無効にすることができません。これはTimestreamの【強み③】にあたるものですね。
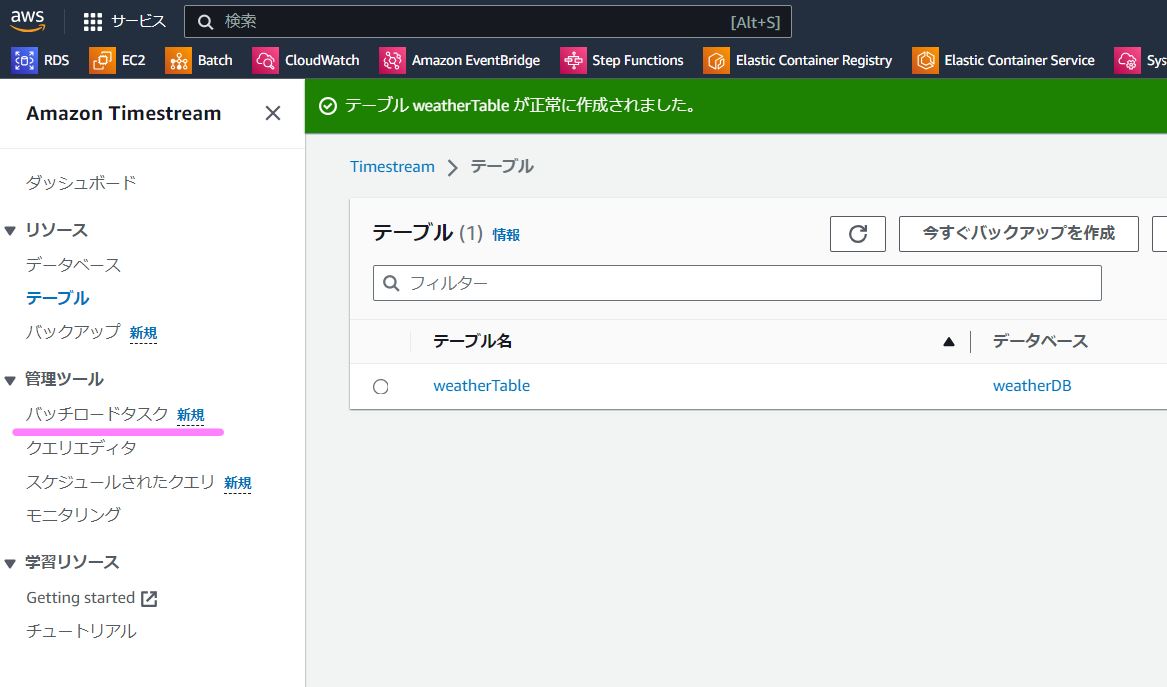
①データベースの作成ができました。
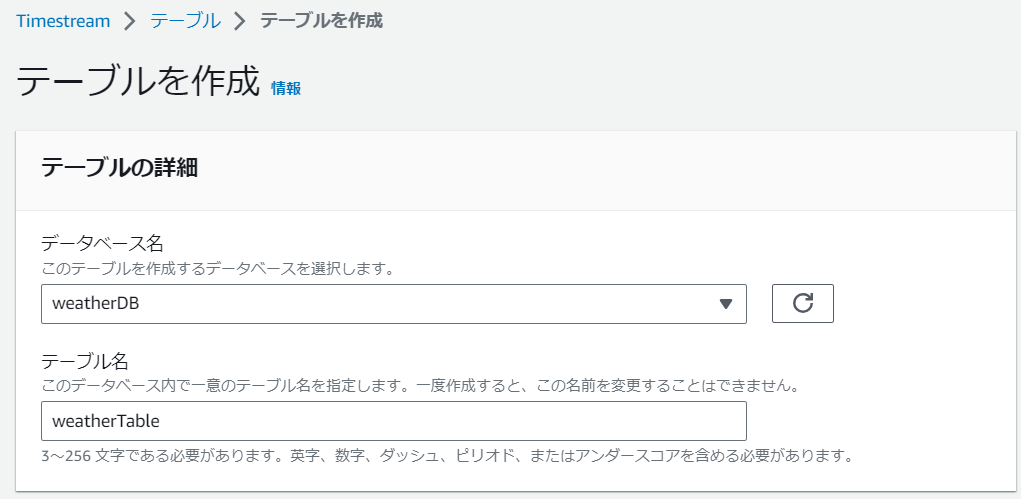
次は②テーブルを作成していきます。左のテーブルを選択して、オレンジ色の「テーブルを作成」をクリックします。
データベース名はプルダウンから先ほどの「weatherDB」を選択します。テーブル名は「weatherTable」としましょう。
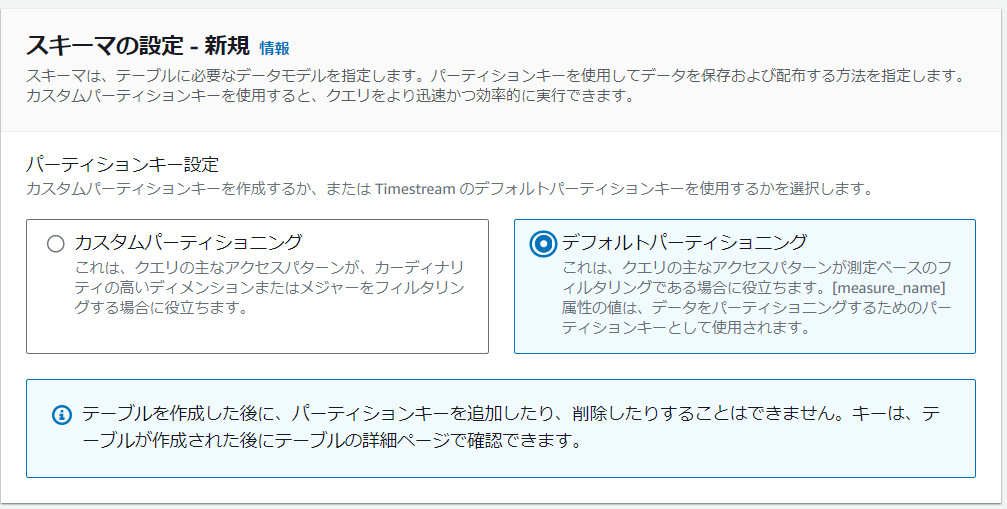
スキーマのところはデフォルトパーティショニングにしましょう。正直ここはまだしっかり理解できていません。ただ後ほど書きますが、どうやら取り込むデータの列として「measure_name」という列が必要なようです。
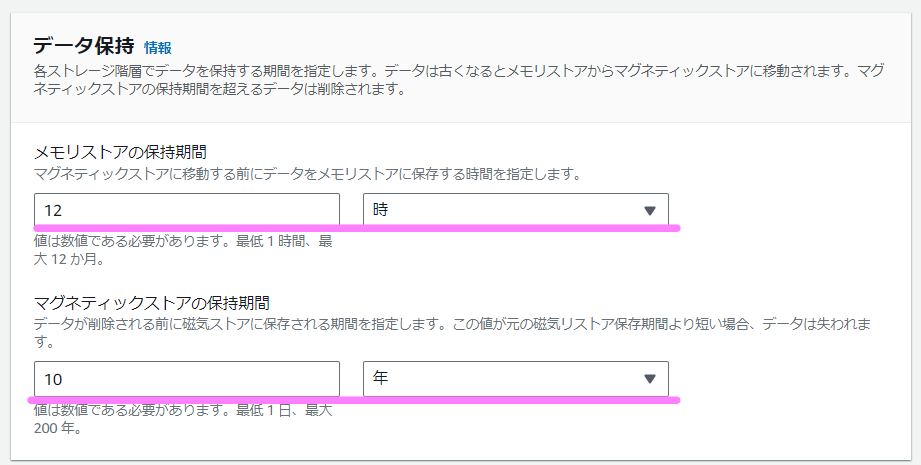
続いてデータ保持関連の部分です。Timestreamの【強み②】に関係する部分です。時系列データをテーブルに格納する際、保存先としてメモリストア、マグネティックストアの2つがあります。投入された時系列データはまずメモリストアに格納され、その後一定期間を経てマグネティックストアに移動されます。マグネティックストアに移動されたあと、一定期間を経て時系列データが削除されます。つまり投入された時系列データは「メモリストア」→「マグネティックストア」→「削除」という生涯を歩むことになります。ここではそれぞれでの保持期間を決めます。
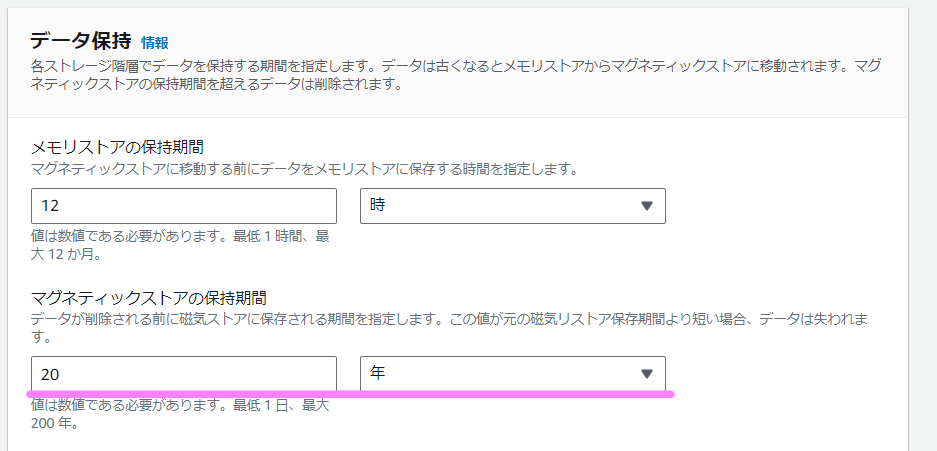
下記の例(デフォルト)では、メモリストアに12時間保存し、それが超えたらマグネティックストアに移動され、そこで10年が過ぎると削除されます。
この「保持期間」が面白くて、実はこの判断基準は時系列データのタイムスタンプになります。つまり上記の場合、(まずメモリストアに書き込まれるので)タイムスタンプがメモリストアの保持期間である12時間前のものだとそもそも投入できません。つまり1日前の時系列データは投入できないのです。判断基準が実施した時刻ではないところが面白いですね。とはいえ、メモリストアの保持期間は最長1年です。ということはどうやっても1年前のデータは投入できないのか・・と悩みました。
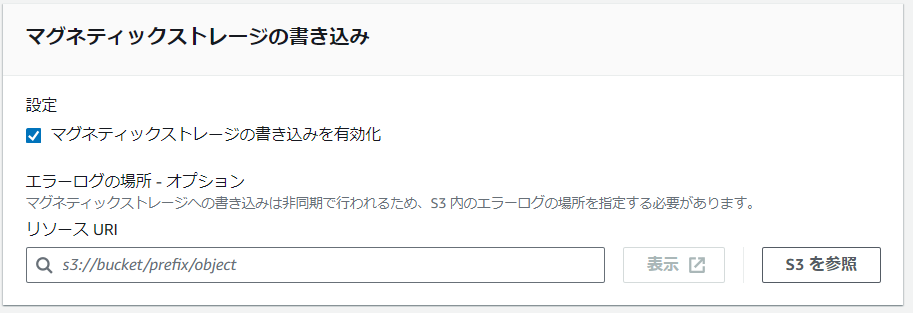
実はその下の設定「マグネティックストレージの書き込みを有効化」をチェックすればマグネティックストレージの保持期間内の時系列データであれば投入できます。
しかし今回は2010年1月1日からのデータなので、約13年前となります。そのため、マグネティックストアの保持期間をデフォルトの10年から増やします。以下のようにすれば大丈夫です。
これで、テーブルが作成できました。
Timestream側の準備ができました。次は気象庁からDLしてきたCSVファイルを、Timestreamの時系列DBに合うような形で整形します。最初はCSVをそのままアップロードすればいいのかと思ってましたが、そう単純ではなかったようで、かなり試行錯誤しました。(10時間くらいかかりました。。)
やることは大きく分けて4点です。
順番に見ていきます。
①欠損データを取り除く
実際気象庁のデータを取得してきて分かったのですが、過去13年のデータの中には、最高気温、最低気温の値が取れていない(データ欠損)しているものもありました。欠損データが混じっていると、うまく取り込めないことが分かったので今回はいったん欠損行は削除しました。(欠損データを含んだまま取り込む方法を知っている方いらっしゃいましたらぜひ教えてください!)
②タイムスタンプをUNIX時間に変更する
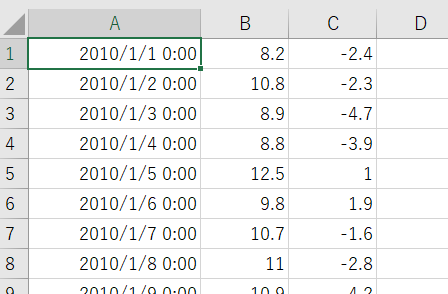
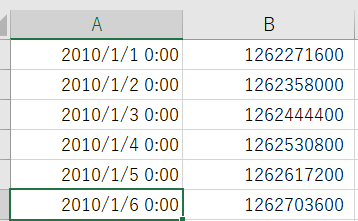
気象庁からDLしてきたCSVファイルの中身は以下のようになっています。時刻が「YYYY/MM/DD・・」となっていますね。これをそのままTimestreamに取り込むことはできず、UNIX時間に変更する必要があります。
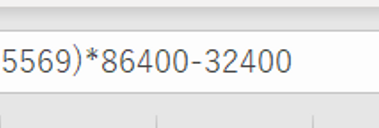
UNIX時間とは1970/1/1からの秒数を数えたものになります。EXCELの上記の時刻表記をUNIX時間に変更するには、以下計算式を使います。
(EXCELの時刻表記 -25569)*86400 - 32400
これを利用すると、タイムスタンプは以下のようになります。これがUNIX時間です。
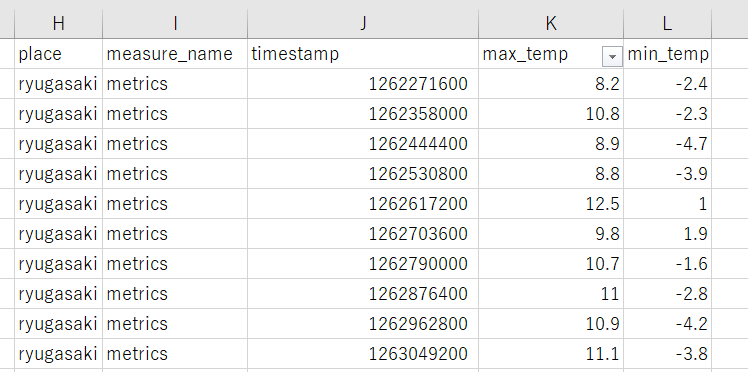
③「place」という列を追加し、そこに「ryugasaki」と入れる。
「place」という列を追加して、全ての項目に「ryugasaki」と入れます。今回は一つの観測拠点しか取得しませんが、複数拠点を取得する場合はここを変更します。
④「measure_name」という列を追加し、そこに「metrics」と入れる
これもデータ投入時にわかった部分ですが、この「measure_name」という列がないとうまくいきませんでした。列を追加し、全ての項目に「metrics」と入れます。
あとは最高気温、最低気温を列にそのまま加えます。ここまでをまとめると以下になります。
この整形したCSVファイルを名前を付けて保存しておきます。
Timestreamの【強み⑤】にある通り、Timestreamは作成したCSVデータをS3から取り込みます。なので、ついでにこのCSVを格納するS3バケットも作成しておきます。S3バケットはTimestreamと同リージョンに作成する必要があるようです。Timestreamの時系列DBは東京リージョンに作成したので、S3バケットも東京リージョンに作成します。名前は任意で大丈夫です。今回は「weather-test-backet」としました。バケットポリシーも特に変更は必要ありませんでした。
このバケットに先ほどの整形したCSVファイルをアップロードします。S3はドラッグ&ドロップでもアップロードできるようになったんですね。
これで取り込む準備ができました。
整形したCSVファイルをS3バケットにアップロードできたので、いよいよTimeStreamの時系列DBに取り込みます。管理ツールの「バッチロードタスク」というものを選択します。(新規とあるように、これは今年の3月から利用できるようになった機能のようです)
オレンジ色の「バッチロードタスクの作成」をクリックします。(たくさん失敗があるのは気にしないでください)
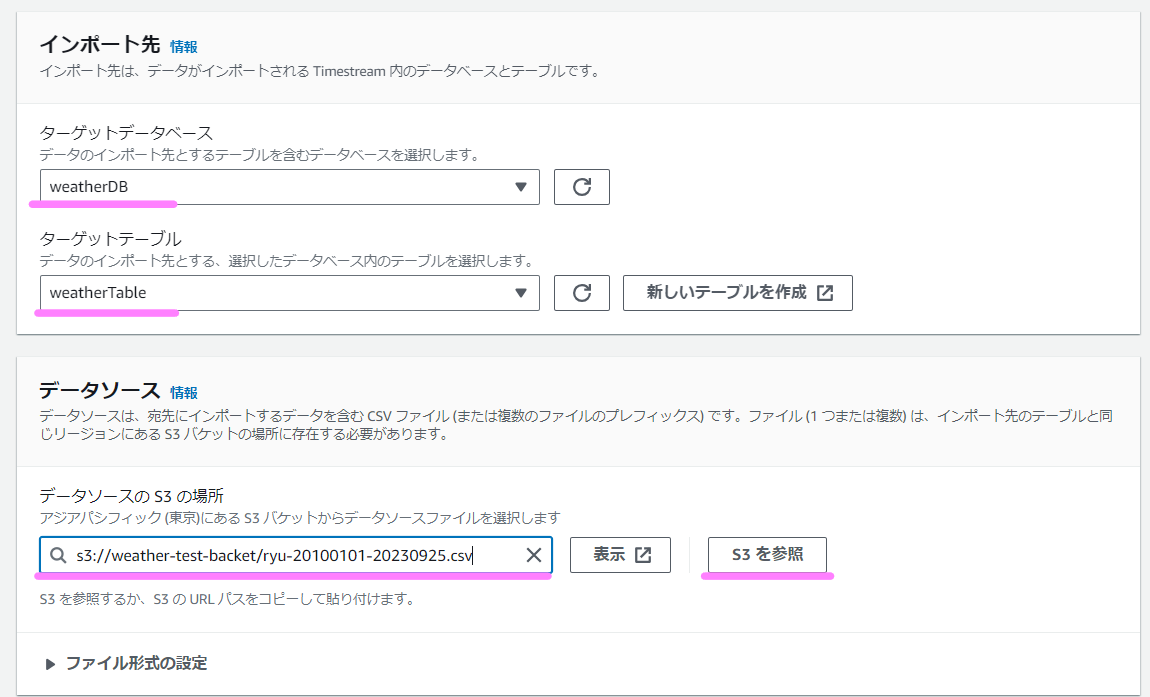
ターゲットデータベース、ターゲットテーブルをプルダウンから選びます。またデータソースは「S3を参照」を押下して先ほどアップロードしたCSVファイルを選択します。
次にデータモデルマッピングの部分です。ここがとても難しかったです。。
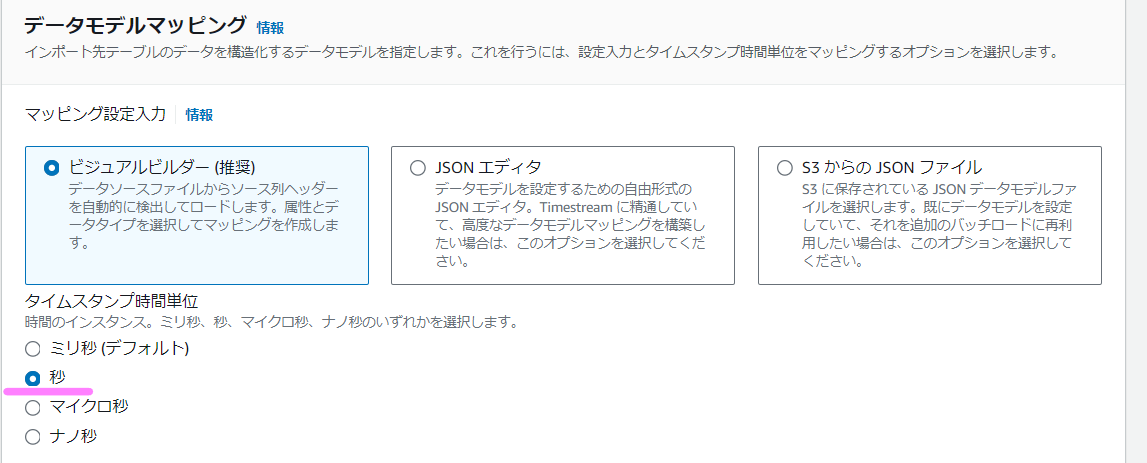
まず、「タイムスタンプ時間単位」ですが、デフォルトはミリ秒となっているかと思いますが、ここを秒に変えます。これをしないと、取り込み時にタイムスタンプの範囲が合っていないと言われエラーとなります。
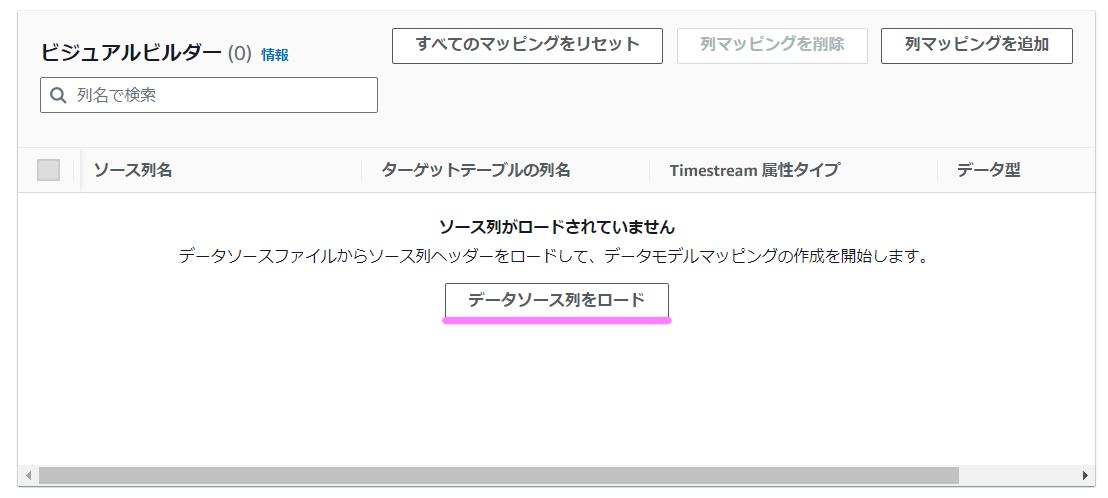
次にビジュアルビルダーのところで、「データソース列をロード」というボタンを押します。
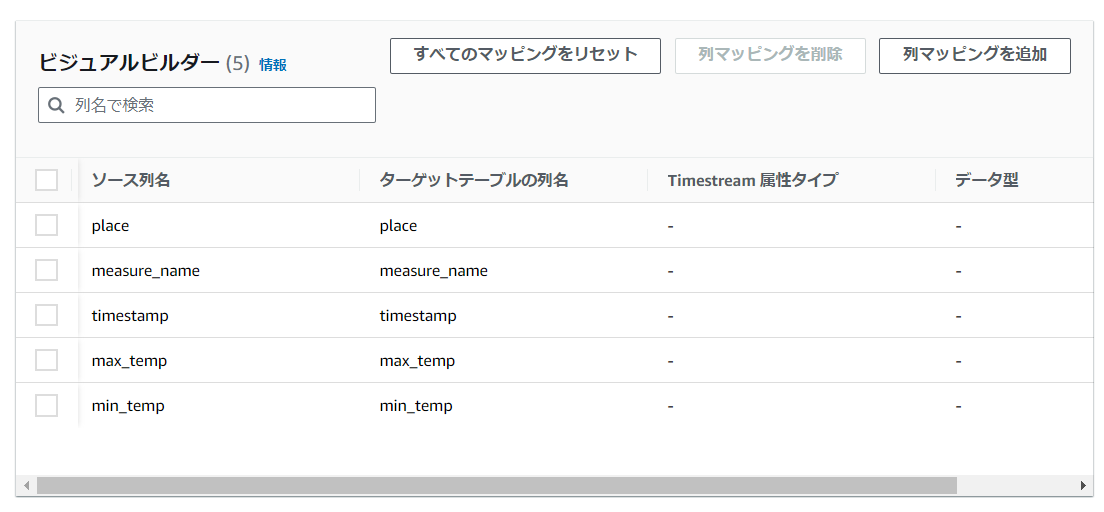
ここで以下のように正しく出てくればOKです。出てこない場合は「measure_name」列がない可能性があります。
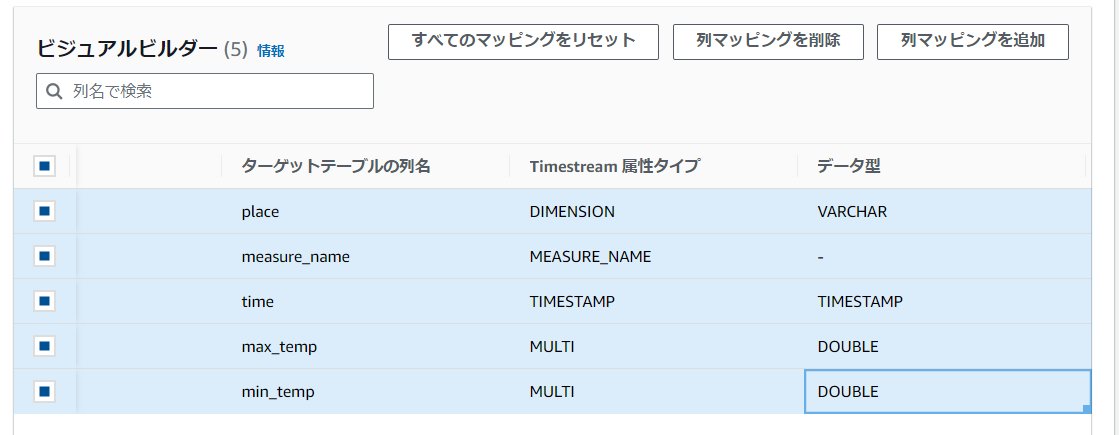
そして、TimeStream属性タイプおよびデータ型をプルダウンで選べるので、以下のように選択します。
DIMENSIONとMEASURE_NAME,TIMESTAMPは必須だったかと思います。実際の測定値はDOUBLE型で定義しています。
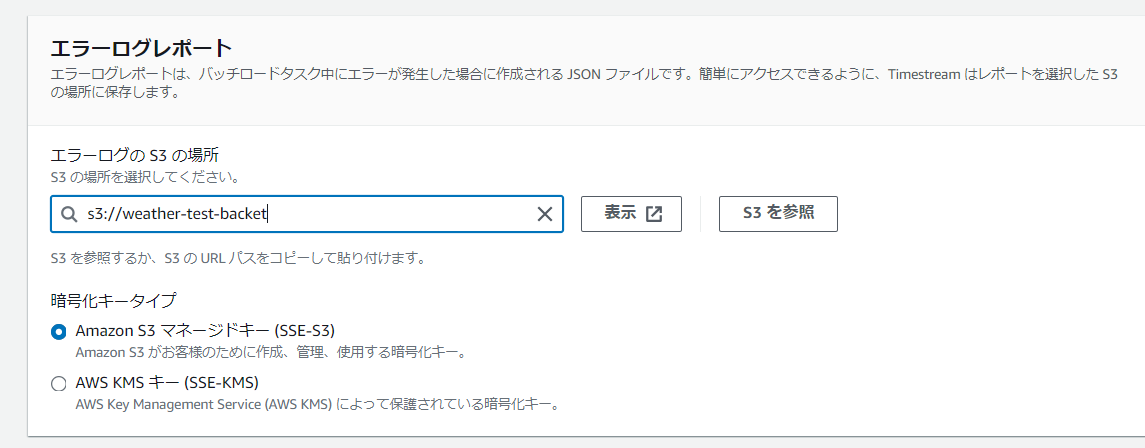
最後にエラーログレポートを格納するS3の場所を定義します。先ほどと同じバケットにしました。
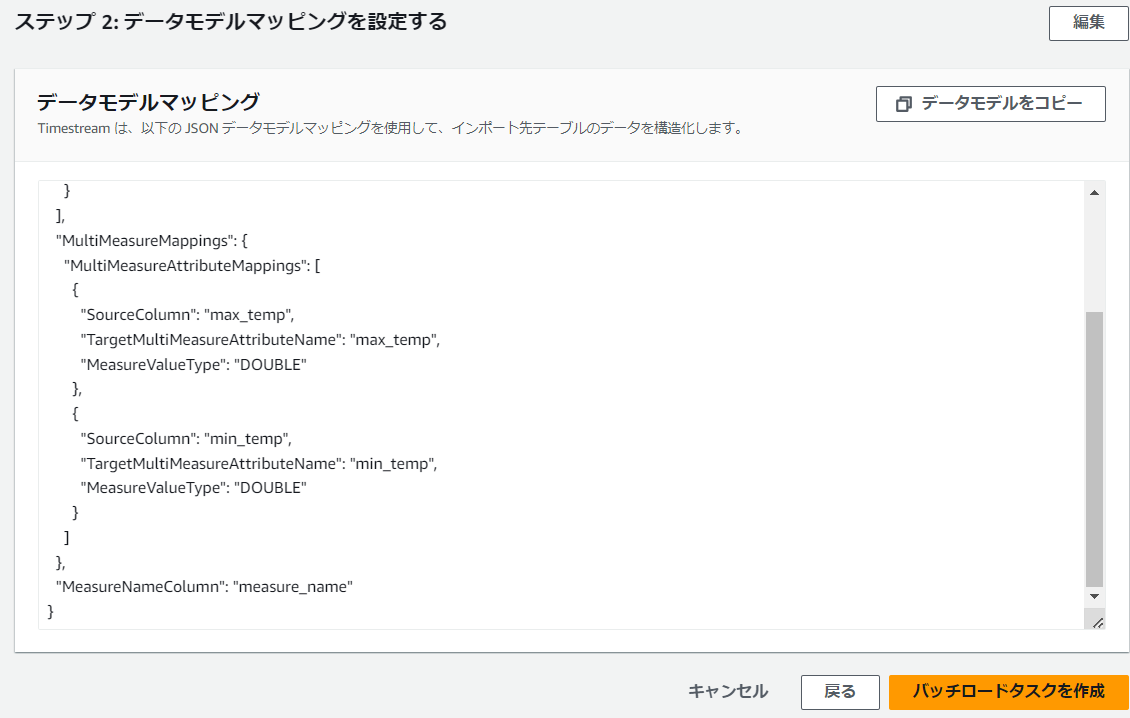
次のページに行き内容確認後、「バッチロードタスクを作成」を押下します。なお、データモデルマッピングは、先ほどの前のページでの設定項目がJSON形式で記載されています。エラーを繰り返すと、毎回同じようにプルダウンから選択・・みたいになるので、これをコピーしておき、次回定義の際はJSONエディタから貼り付けると便利です。私は何度もやり直し再設定する途中でこのやり方に気づき、少し楽になりました。
バッチロードタスクが動きます。
完了しました!
これは、気象庁のCSVデータをTimestreamの時系列DBに保存できたことを意味します。
取り込みがうまくいきましたので、時系列DBの中身を見てみましょう。Timestreamには「クエリエディタ」というサービスがあり、SQL文を利用して中身のデータを参照できます。管理ツールの「クエリエディタ」を押下します。
これがクエリエディタです。RDBにおいてクライアントツールでDB接続したときのようにここにSQL文を記載することで取り込んだ時系列データの参照ができます。
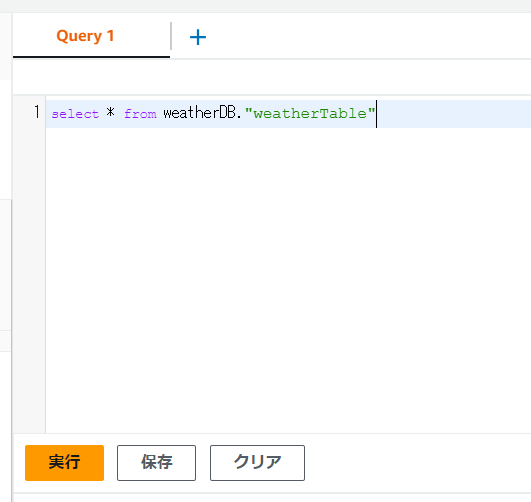
まずちゃんと取り込まれているかどうか、見てみましょう。以下のようなクエリを実行します。
ちゃんと結果取れてますね!
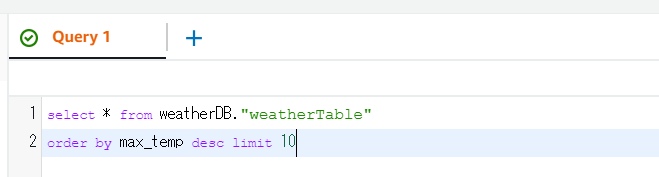
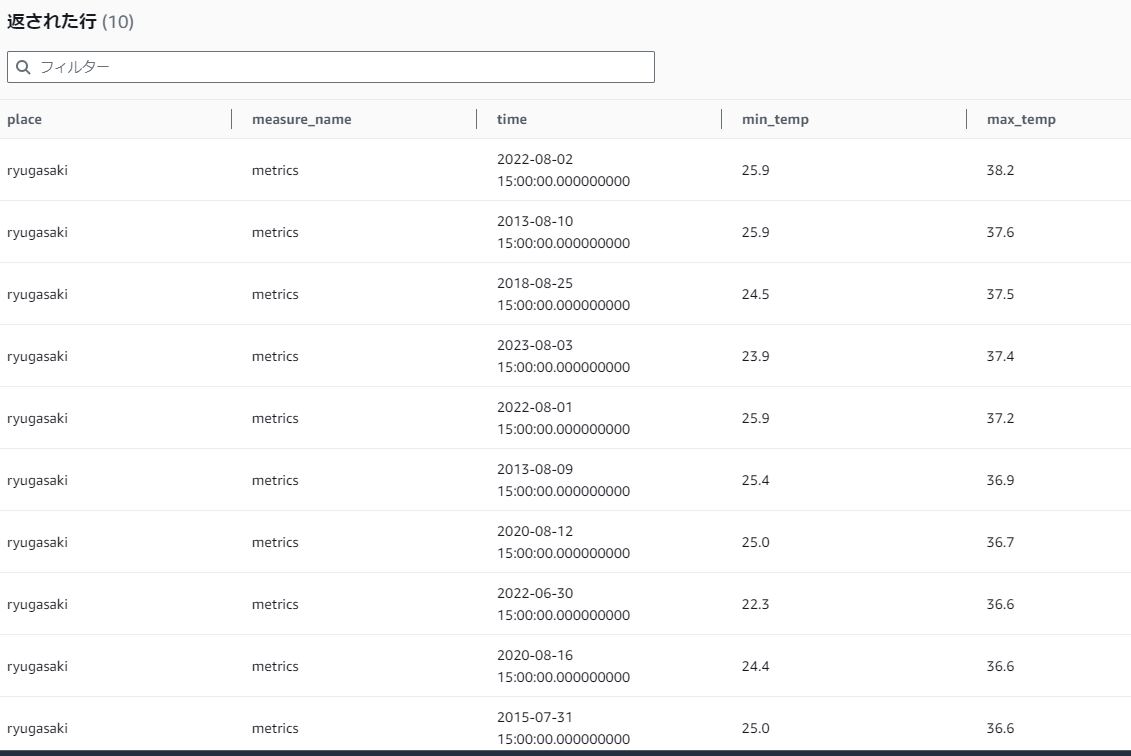
それでは、過去13年間でもっとも気温が高かったベスト10を表示させてみましょう。
ちゃんと取れているようですね!
ベスト10を見ている限りでは、今年のランクインは1件だけですね。去年(2022年)は3件ランクインしているので、データでは去年のほうが暑かったみたいですね。(あくまで龍ヶ崎市の場合)
ちなみにこのような形式をそのままRDBに保存するのはとても難しいということが容易に想像できるかと思います。(まず主キーが厳しいですよね・・。)このような時系列データを迅速に格納、処理できるのが時系列DBの特徴ですね。
Timestreamには時系列データは保存されますが、それを可視化して表示させるには別のサービスと組み合わせることになります。可視化ツールとして、AWSのQuickSightがあります。利用したことがなかったのですが1か月間無料のようですので今回作成したTimestreamと連携させてみました。
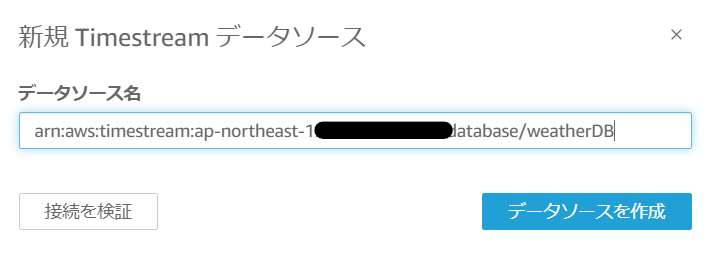
QuickSightでアカウントを作成し、データセットにて「Timestream」を選択します。以下の通り、ほかにもたくさんのデータソースの可視化に対応しているようです。
接続先のデータソース名としては、TimestreamのデータベースのARNを入力します。
「接続を検証」して、緑チェックになればOKです。
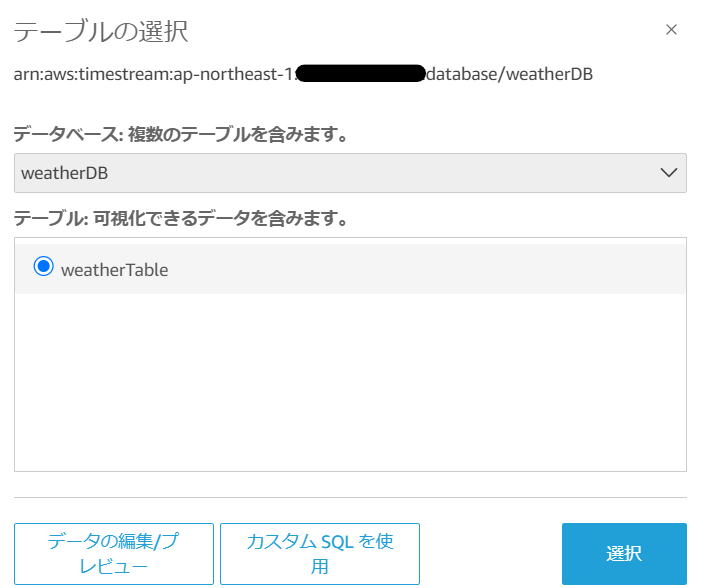
そうすると、テーブルの選択で先ほど作成したweatherTableが表示されます。この時点でちゃんと連携がとれているんだと安心しますね。
テーブルを選択すると、先ほどのTimestreamの時系列DBで取り込んだ気象データが、全てQuickSight側から参照できるようになります。あとはこれを可視化していきます。
最高気温と最低気温の変遷
過去の最高気温の記録分布。最頻値は「22.6℃」で過去31回記録されていることがわかります。
最低気温の変遷値など。例えば最頻値は「-1.3℃」で過去30回記録されていることがわかります。また過去最低の気温は「-8.8℃」だったこともわかります。
QuickSightのいろんな機能を使えば、もっといろいろ加工したり、かっこよく表示したりすることができるのだと思いますが、一応、初めて触ってみた感じでここまで表示することはできました。
時系列DBサービス「Timestream」および、そのデータを「QuickSight」で可視化するということをやってきました。データ題材としては気象庁のオープンデータを利用し、新機能「バッチロードタスク」を使って取り込みました。いかがでしたでしょうか。実はここまでやってきて言うのもなんですが、ある一都市の数年分のデータをグラフ表示するだけであれば、EXCEL加工で十分だということもわかりました(笑)
しかし、100万件を超えるような時系列データや、1日に数億、数兆も来るようなリクエストに対して、それらをスピーディーに処理し、安全に格納し、古くなったデータは自動的に削除する機能をEXCELやRDBは備えていません。今回は気象データを利用しましたが、他にも様々な時系列データを用いて過去の動きや傾向から将来を予測したりすることもできるかと思います。例えば勤怠、PCのリソース状況、経営情報、部会やミッション参加率など、自社の様々な時系列データを時系列DBに格納して可視化し、会社の方向性を決めていくことも可能かと思います。もちろんその際にはQuickSightのような可視化ツールや、予測を手助けするような機械学習サービスも必要でしょう。少しの加工は必要でしょうが、元ネタとしてCSVファイルだけあればいいというのは、導入も簡単でいいのではないかなと思いました。
来年の夏は、少し涼しくなるといいですね。
読んで下さってありがとうございました!
本記事の執筆にあたり、多数のサイトを参考にさせていただきました。この場をお借りして御礼申し上げます。

/assets/images/4011356/original/888630f0-8d41-4054-8de3-5be6c86f98d7?1566135134)
![]()




/assets/images/11403610/original/888630f0-8d41-4054-8de3-5be6c86f98d7?1670285641)